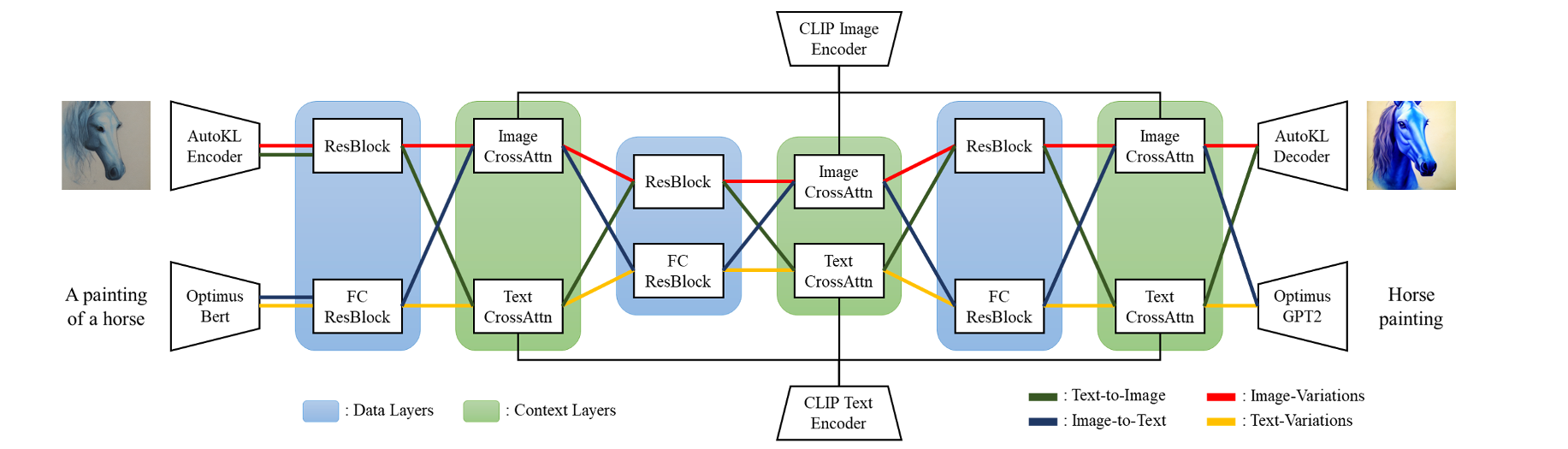
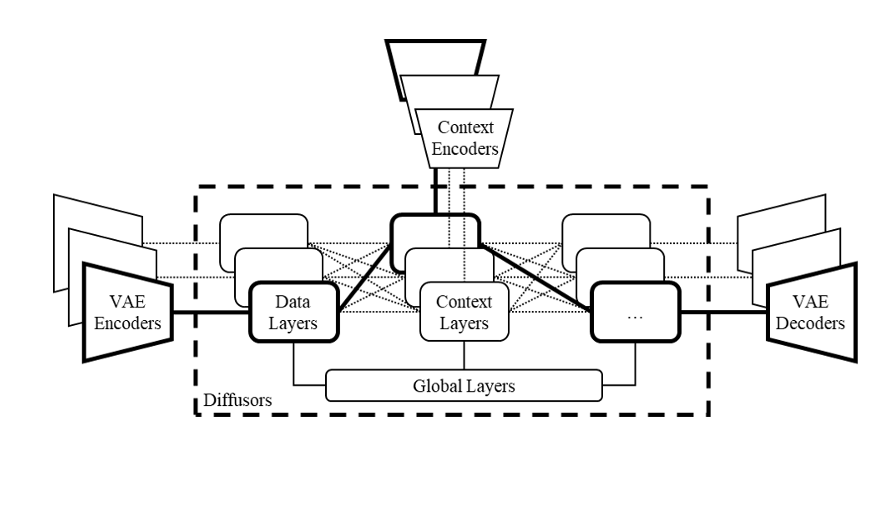
Diffusion multimodal is a generative AI model that combines text and image diffusion models to generate images from text prompts. It builds upon the capabilities of existing diffusion models by incorporating a multimodal approach that allows for a more comprehensive understanding of the relationship between text and images.
The benefits of diffusion multimodal are numerous. First, it enables the generation of high-quality images that are both visually appealing and semantically coherent. Second, it allows for fine-grained control over the image generation process, enabling users to specify specific attributes of the desired image. Third, it can be used for a wide range of applications, including image editing, image generation, and image-based storytelling.
Diffusion multimodal is still in its early stages of development, but it has the potential to revolutionize the way we interact with images and text. By providing a powerful tool for generating and editing images, it can open up new possibilities for creativity and expression.
Diffusion Multimodal
Diffusion multimodal, a cutting-edge generative AI model, seamlessly blends text and image diffusion models. This integration empowers users with unparalleled capabilities in image generation from textual descriptions. Its remarkable advantages stem from several key aspects:
- Multimodal Fusion: Interwoven text and image modalities for enhanced understanding.
- Coherent Generation: Production of semantically aligned, visually stunning images.
- Controllable Synthesis: Precise manipulation of image attributes, catering to specific preferences.
- Diverse Applications: Limitless possibilities in image editing, generation, and storytelling.
- Fine-tuning Potential: Adaptable to specialized domains, enhancing accuracy and relevance.
- Novel Artistic Expression: Unlocks new avenues for creative exploration and visual communication.
In essence, diffusion multimodal bridges the gap between language and imagery, offering unprecedented control and flexibility in image creation. Its potential applications span far and wide, promising to revolutionize industries such as media, entertainment, and design.
1. Multimodal Fusion
Multimodal fusion, a cornerstone of diffusion multimodal, plays a pivotal role in enhancing the model's understanding of the relationship between text and images. By seamlessly intertwining these modalities, diffusion multimodal gains the ability to generate images that are not only visually appealing but alsosemantically coherent with the provided text prompts. This fusion process enables the model to leverage the strengths of both text and image data, resulting in a more comprehensive and nuanced understanding of the desired image.
The importance of multimodal fusion in diffusion multimodal is further highlighted by its practical applications. For instance, in the field of image editing, multimodal fusion allows users to manipulate and enhance images with greater precision and control. By combining text-based instructions with visual cues, users can specify the desired changes in a more intuitive and efficient manner. Additionally, multimodal fusion opens up new possibilities for image generation, enabling users to create novel and unique images that may not have been possible with traditional text-based or image-based models alone.
In summary, multimodal fusion is a crucial component of diffusion multimodal, providing the model with the ability to fuse text and image modalities for enhanced understanding. This fusion process leads to the generation of semantically coherent and visually stunning images, unlocking a wide range of applications in image editing, generation, and beyond.
2. Coherent Generation
Coherent Generation, a defining characteristic of diffusion multimodal, refers to the model's ability to generate images that are not only visually appealing but also semantically aligned with the provided text prompts. This remarkable capability stems from the model's deep understanding of the relationship between text and images, enabling it to produce images that are both aesthetically pleasing and meaningful.
- Semantic Alignment: Diffusion multimodal excels in generating images that accurately reflect the content and context of the input text. The model's ability to comprehend the semantics of the text allows it to produce images that are visually consistent with the described scene or concept.
- Visual Consistency: Beyond semantic alignment, diffusion multimodal also ensures that the generated images are visually coherent and realistic. The model takes into account factors such as lighting, perspective, and object proportions to create images that are visually believable and free from distortions or artifacts.
- Attention to Detail: Diffusion multimodal pays meticulous attention to detail, capturing even the most intricate aspects of the described scene. The model's ability to generate high-resolution images allows for close examination and appreciation of the fine details, contributing to the overall realism and immersion of the generated images.
- Artistic Quality: While maintaining semantic coherence and visual consistency, diffusion multimodal also produces images that possess an inherent artistic quality. The model's ability to combine different elements and styles in a harmonious manner results in visually striking and aesthetically pleasing images that evoke emotions and inspire creativity.
In summary, Coherent Generation is a cornerstone of diffusion multimodal, empowering the model to produce semantically aligned, visually stunning images. This capability opens up a wide range of applications in fields such as image editing, storytelling, and visual effects, where the generation of high-quality and meaningful images is paramount.
3. Controllable Synthesis
Controllable Synthesis is a defining feature of diffusion multimodal, empowering users with the ability to manipulate and modify generated images with unparalleled precision. This fine-grained control extends to a wide range of image attributes, allowing users to tailor the generated images to their specific preferences and requirements.
- Attribute Editing: Diffusion multimodal provides users with the ability to modify specific attributes of the generated images, such as the size, shape, color, and texture of objects. This level of control allows users to refine and enhance the generated images, ensuring that they meet their specific requirements.
- Stylistic Transfer: Controllable Synthesis also enables users to apply different artistic styles to the generated images. By incorporating elements from various artistic movements and techniques, users can transform the images into unique and visually striking creations.
- Image Enhancement: Diffusion multimodal can be used to enhance existing images, memperbaiki the quality, and adding new elements or effects. This capability opens up new possibilities for image editing and restoration, allowing users to improve the visual appeal and impact of their images.
- Image Generation from Sketches: Controllable Synthesis allows users to generate complete images from rough sketches or outlines. This feature is particularly useful for concept artists and designers, enabling them to quickly and efficiently create high-quality images from their initial ideas.
In summary, Controllable Synthesis is a powerful aspect of diffusion multimodal that provides users with precise control over the generation and manipulation of images. This fine-grained control opens up a wide range of possibilities in fields such as image editing, digital art, and visual effects, empowering users to bring their creative visions to life.
4. Diverse Applications
Diffusion multimodal unlocks a world of diverse applications, revolutionizing the fields of image editing, generation, and storytelling. Its unique capabilities open up endless possibilities for creative expression and practical problem-solving.
- Photorealistic Image Editing:
Diffusion multimodal empowers users to edit images with remarkable precision and realism. From subtle touch-ups to complex manipulations, the model's ability to understand and modify image content enables seamless editing, enhancing the quality and impact of photographs.
- Novel Image Generation:
Diffusion multimodal goes beyond editing, allowing users to generate completely new images from scratch. By combining text prompts with its deep understanding of visual concepts, the model can create unique and captivating images that push the boundaries of imagination.
- Immersive Storytelling:
Diffusion multimodal has found a home in storytelling, enabling the creation of visually stunning and emotionally resonant narratives. By generating images that align with the flow and tone of a story, the model enhances reader engagement and brings stories to life in new and exciting ways.
- Concept Art and Design:
In the realm of concept art and design, diffusion multimodal serves as a powerful tool for ideation and exploration. Designers can quickly generate visual representations of their concepts, experiment with different styles, and refine their designs through iterative cycles of generation and refinement.
These diverse applications are just the tip of the iceberg for diffusion multimodal. As the technology continues to evolve, we can expect even more innovative and groundbreaking uses for this transformative AI model.
5. Fine-tuning Potential
Diffusion multimodal excels in adapting to specialized domains, enhancing its accuracy and relevance for specific tasks. This fine-tuning potential stems from the model's ability to incorporate domain-specific knowledge and tailor its image generation process accordingly.
- Medical Imaging:
In medical imaging, diffusion multimodal can be fine-tuned to generate realistic and accurate medical images, such as MRI scans or X-rays. By incorporating medical knowledge into the training process, the model learns to identify and highlight relevant anatomical structures, aiding in diagnosis and treatment planning.
- Fashion Design:
For fashion design, diffusion multimodal can be adapted to generate diverse and stylish clothing items. The model can be trained on a dataset of fashion images, learning the intricacies of different fabrics, patterns, and silhouettes. This enables designers to explore new ideas and create garments that meet specific aesthetic or functional requirements.
- Architecture and Design:
In architecture and design, diffusion multimodal can generate realistic and detailed architectural renderings. By leveraging domain-specific knowledge, the model can accurately represent materials, lighting, and spatial relationships. This capability supports architects and designers in visualizing and refining their designs before construction.
- Scientific Visualization:
Diffusion multimodal can contribute to scientific visualization by generating images that illustrate complex scientific concepts. The model can be fine-tuned on scientific datasets to learn the visual representation of data, enabling researchers to communicate their findings in a visually appealing and accessible manner.
The fine-tuning potential of diffusion multimodal empowers it to address a wide range of specialized applications, enhancing its effectiveness and relevance in various fields. By incorporating domain-specific knowledge, the model can adapt to the unique challenges and requirements of each domain, producing high-quality and meaningful images that drive innovation and problem-solving.
6. Novel Artistic Expression
Diffusion multimodal has revolutionized artistic expression by unlocking new avenues for creative exploration and visual communication. Its ability to generate visually stunning and semantically coherent images from text prompts has empowered artists and designers to explore their creativity in unprecedented ways.
One of the key aspects of diffusion multimodal that contributes to its significance in artistic expression is its ability to bridge the gap between language and imagery. By combining text and image modalities, diffusion multimodal enables artists to express their ideas and concepts through a unique blend of words and visuals. This opens up new possibilities for storytelling, concept art, and visual experimentation.
Diffusion multimodal has also gained traction in the fashion industry, where it is used to generate novel and inspiring designs. Fashion designers can leverage the model's capabilities to explore different styles, fabrics, and patterns, pushing the boundaries of their creativity and producing designs that are both visually appealing and commercially viable.
Furthermore, diffusion multimodal has found applications in architecture and interior design. Architects and designers can use the model to generate realistic and detailed renderings of their designs, helping them visualize and refine their concepts before construction. This capability streamlines the design process and enhances the communication between architects, designers, and clients.
In summary, diffusion multimodal's ability to unlock novel artistic expression has had a profound impact on various creative fields. By empowering artists, designers, and architects with the tools to explore their creativity and communicate their ideas visually, diffusion multimodal is shaping the future of artistic expression and visual communication.
Frequently Asked Questions (FAQs) on Diffusion Multimodal
This section addresses common questions and misconceptions surrounding diffusion multimodal, providing clear and informative answers.
Question 1: What is diffusion multimodal and how does it work?
Answer: Diffusion multimodal is a cutting-edge generative AI model that combines text and image diffusion models. It generates images from text prompts by progressively refining an initial noise field, guided by both the text and image data. Through this process, diffusion multimodal produces high-quality images that align with the semantic content of the text.
Question 2: What are the key advantages of using diffusion multimodal?
Answer: Diffusion multimodal offers several key advantages:
- Generation of semantically coherent and visually appealing images.
- Precise control over image generation, allowing for fine-tuning of specific attributes.
- Wide range of applications, including image editing, generation, and storytelling.
- Adaptability to specialized domains, enhancing accuracy and relevance in specific fields.
Question 3: How is diffusion multimodal different from traditional generative AI models?
Answer: Diffusion multimodal distinguishes itself from traditional generative AI models by combining text and image modalities. This fusion enables a deeper understanding of the relationship between text and images, leading to more semantically coherent and visually realistic image generation.
Question 4: What are some practical applications of diffusion multimodal?
Answer: Diffusion multimodal finds applications in various fields, including:
- Photorealistic image editing and enhancement
- Generation of novel and unique images for creative projects
- Concept art and design exploration
- Scientific visualization and communication
- Medical imaging and diagnosis
Question 5: How can I access and use diffusion multimodal?
Answer: Diffusion multimodal is accessible through various platforms and APIs provided by research institutions and tech companies. Developers and users can integrate the model into their applications or utilize pre-built tools to generate and edit images based on text prompts.
Question 6: What are the limitations and future prospects of diffusion multimodal?
Answer: While diffusion multimodal shows promising capabilities, it has limitations such as potential biases in image generation. Ongoing research focuses on addressing these limitations and exploring new applications, making diffusion multimodal an exciting and evolving field in AI.
In summary, diffusion multimodal is a groundbreaking AI model that combines text and image modalities, opening up new possibilities in image generation and editing. Its diverse applications and continuous development make it a valuable tool for various industries and creative endeavors.
Stay tuned for the next section of our article, where we delve deeper into the technical details and use cases of diffusion multimodal.
Harnessing Diffusion Multimodal for Exceptional Image Generation
Diffusion multimodal, a groundbreaking AI model, empowers users to generate compelling and semantically coherent images from mere text prompts. To maximize its potential, consider these valuable tips:
Tip 1: Craft Precise Text Prompts: Compose clear and concise text prompts that accurately convey your desired image. Avoid ambiguity and provide specific details to guide the model toward the intended outcome.
Tip 2: Leverage Negative Prompts: Instruct the model on what not to generate by employing negative prompts. This technique helps refine the results and eliminates unwanted elements, ensuring greater control over the image generation process.
Tip 3: Experiment with Image-to-Image Generation: Utilize diffusion multimodal's image-to-image generation capabilities to transform existing images. Provide an initial image and a text prompt to modify specific aspects, merge elements, or create entirely new compositions.
Tip 4: Explore Latent Space Interpolation: Navigate the latent space of diffusion multimodal to generate a series of images that smoothly transition between two distinct prompts. This technique allows for the exploration of gradual changes and the discovery of novel visual concepts.
Tip 5: Leverage Fine-tuning for Domain Adaptation: Fine-tune the diffusion multimodal model on domain-specific datasets to enhance its performance in specialized fields. This customization improves the model's understanding of specific concepts and enables tailored image generation for various applications.
Tip 6: Utilize Advanced Sampling Techniques: Employ advanced sampling methods, such as DreamBooth or guided diffusion, to refine the image generation process. These techniques provide greater control over the image's style, composition, and adherence to the text prompt.
Tip 7: Explore Model Architectures and Hyperparameters: Investigate different diffusion multimodal model architectures and hyperparameter settings to optimize the image generation process. Experiment with model size, depth, and training parameters to achieve the desired balance between image quality and computational efficiency.
Tip 8: Monitor and Evaluate Results: Continuously monitor and evaluate the generated images to assess their quality and alignment with the intended purpose. Use metrics such as FID (Frchet Inception Distance) and human evaluation to refine the model's performance and ensure satisfactory outcomes.
By incorporating these tips into your diffusion multimodal workflow, you can unlock its full potential and harness its capabilities to generate exceptional images that push the boundaries of creativity and innovation.
In conclusion, diffusion multimodal stands as a transformative tool for image generation, offering unprecedented control and flexibility. By embracing these tips, you can master this powerful technology and unlock its limitless possibilities.
Conclusion
Diffusion multimodal has emerged as a groundbreaking generative AI model that revolutionizes image generation. Its ability to fuse text and image modalities empowers users with unprecedented control and flexibility, opening up a world of creative possibilities and practical applications.
Throughout this article, we have explored the inner workings of diffusion multimodal, delving into its core principles, diverse applications, and practical tips for maximizing its potential. As the technology continues to evolve, we can anticipate even more transformative capabilities and applications in the realm of image generation and beyond.
Diffusion multimodal stands as a testament to the ever-expanding capabilities of AI, pushing the boundaries of human creativity and innovation. By embracing this powerful tool and continuing to explore its potential, we can unlock a future where images and language seamlessly intertwine, empowering us to express our ideas and visions in ways never before imagined.
You Might Also Like
The Ultimate Guide To Daniel Mathew - Discover Everything You Need To KnowGet To Know Marilyn Mendonca: The Rising Star Of Brazilian Music
Discover The Ultimate Guide To Empirical Rules
The Complete Guide To CK Timeline: Creating Dynamic Visual History Lines
Write A Letter To Apologize For The Mess
Article Recommendations
- Stockwecom Unlocking Insights Into The World Of Finance And Investment
- Exploring 1997523665 A Hidden Gem Of Scenic Beauty And Cultural Significance
- Discover The Transformative Power Of Living Alchemy